Chatbot User Experience
Navigate to the browser and open the Workshop UI. The UI is displayed as follows:
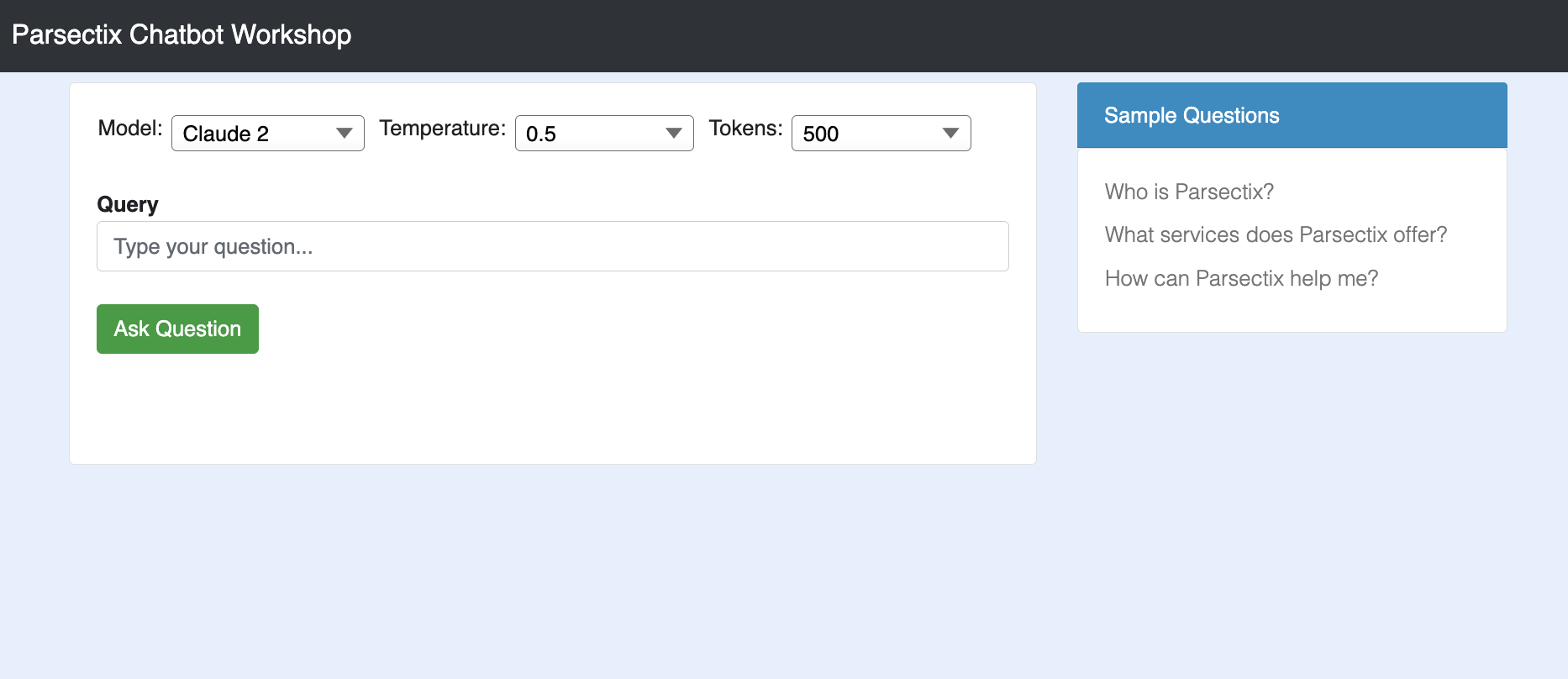
When you enter a question, you might expect an answer that is accompanied by relevant document references. However, if no supporting document or data source is available, you might receive a response that states: “Sorry, I don’t have the answer.”
Try some of the following sample questions, and review the generated responses by Amazon Bedrock FMs.
Who is Parsectix?
What services does Parsectix offer?
What is the population of Cyprus?
You can experiment with various prompt parameters (such as model temperature and max tokens) to compare and fine-tune your responses.
Inference parameters
Inference parameters are values that you can adjust to limit or influence the model response. The following categories of parameters are commonly found across different models.
Prompt: a textual input given to the model to initiate a response. A prompt can be in the form of a question, statement, or incomplete sentence. The quality and specificity of the prompt can greatly affect the output. In the next task, you will experience various prompt engineering methods.
Temperature: It’s a value between 0 and 1, and it regulates the creativity of LLMs’ responses. Use lower temperature if you want more deterministic responses, and use higher temperature if you want more creative or different responses for the same prompt from LLMs on Amazon Bedrock.
Tokens: Limits the length of the generated response. You can set a maximum number of tokens to control the length of the output.