Index Data with Kendra
Amazon Kendra
Amazon Kendra is a highly available managed search service powered by machine learning (ML). Kendra is designed to enable organizations to index their internal data sources and use natural language queries to find the information they need from within their vast content repositories.
The Amazon Kendra index and Amazon S3 data source were created in the previous step. In this task, we will index the documents we want to use as context for our Chatbot.
-
Upload sample documents to S3
cd ~/environment/parsectix-chatbot-workshop/backend-infrastructure aws s3 cp sample-documents s3://$BUCKET_NAME/sample-documents/ --recursive -
Navigate to Kendra on AWS Console through this URL - https://us-east-1.console.aws.amazon.com/kendra/home?region=us-east-1#indexes . Identify your index and click on it.
-
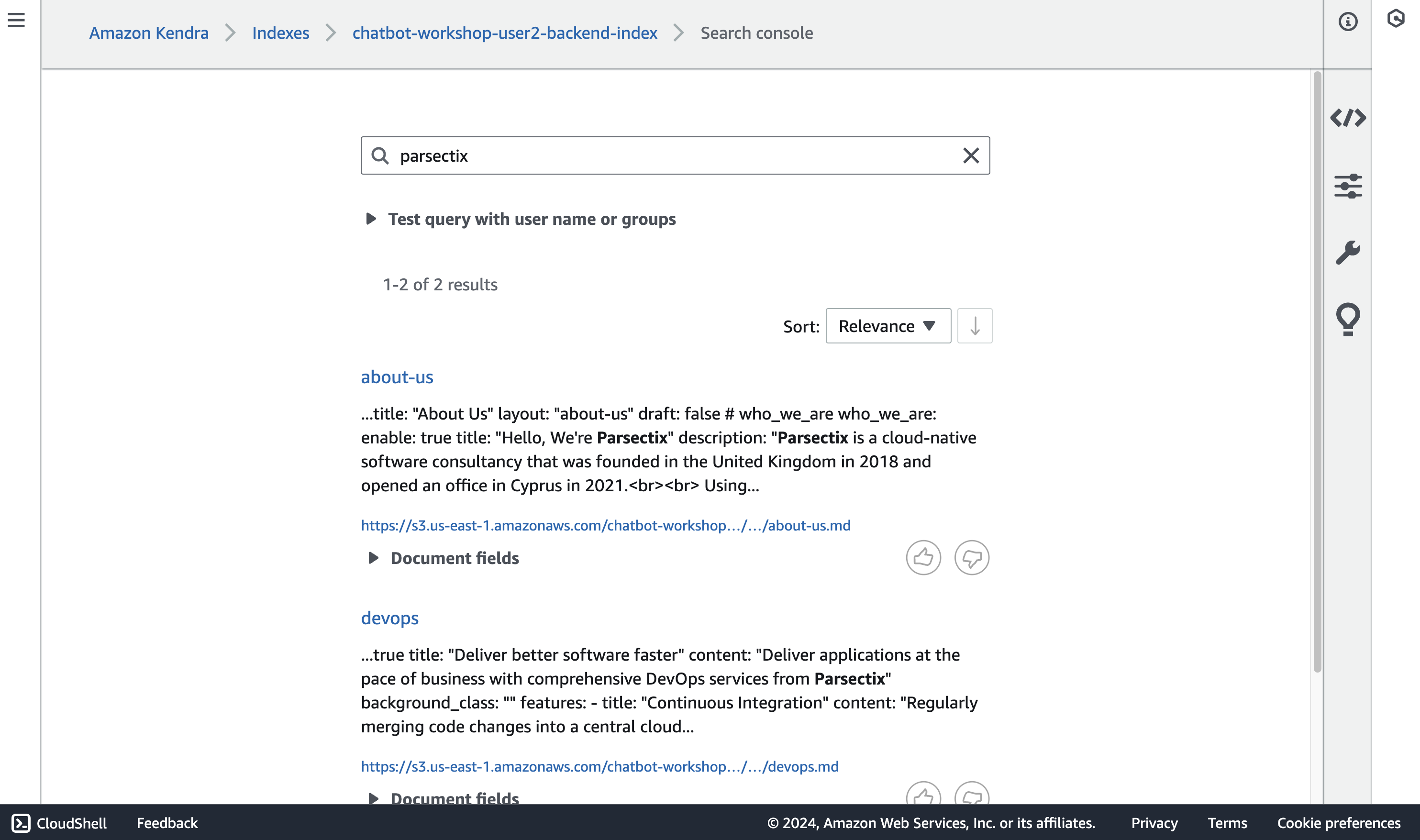
Click on Search indexed context and search for “Parsectix”. What is the response?
-
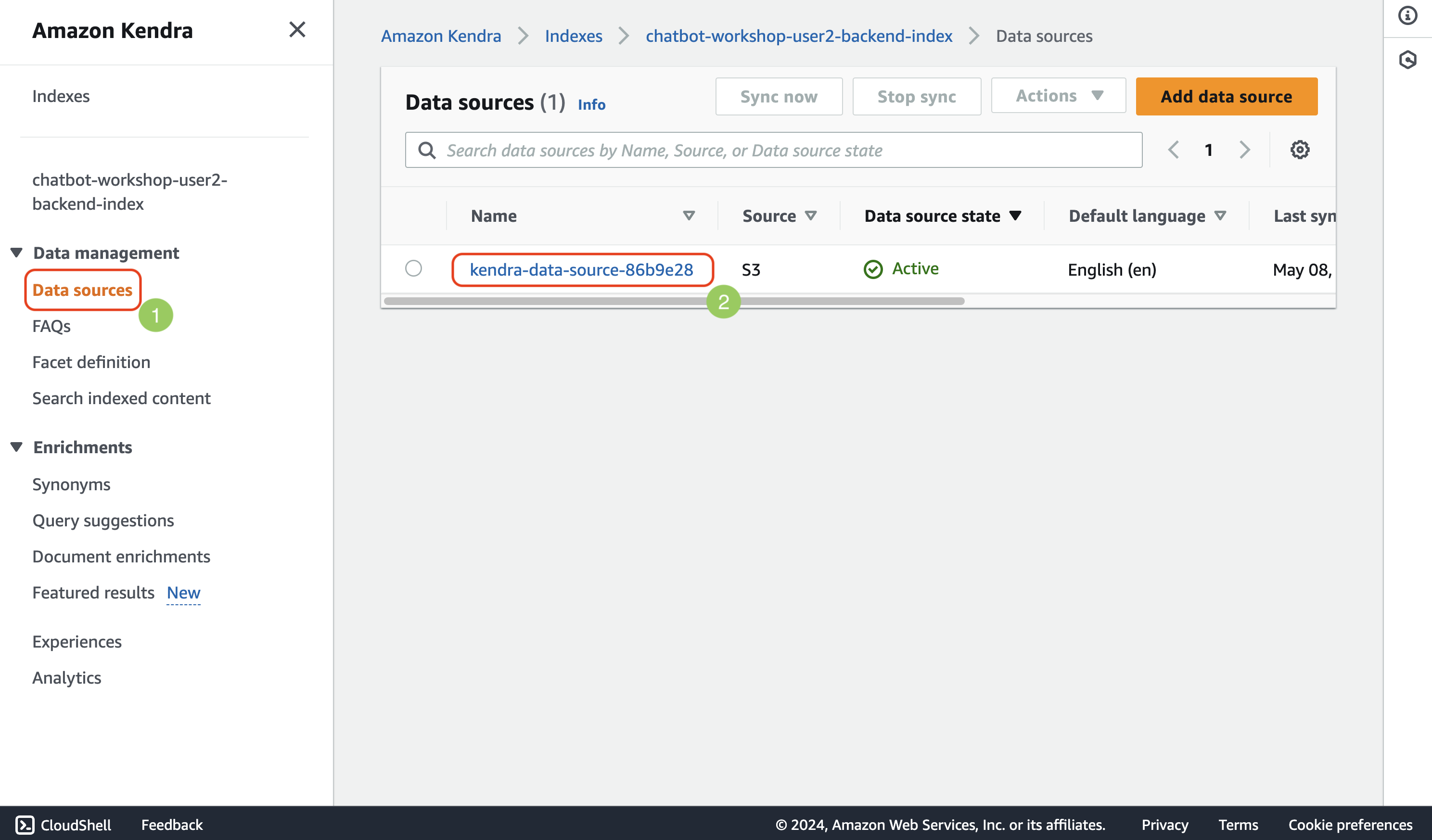
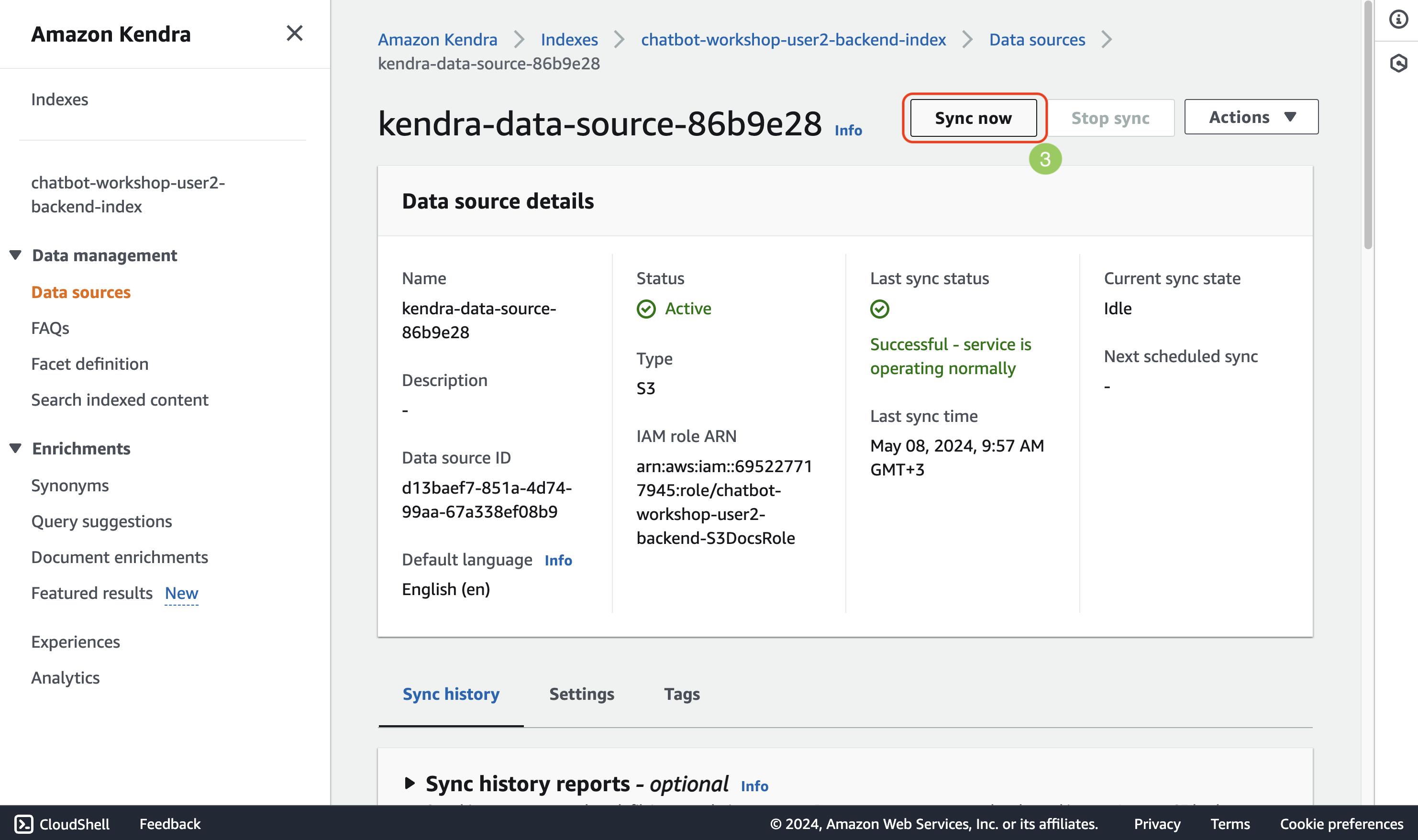
The result is expected because we haven’t indexed our data yet. To start indexing all the documents from the sample-documents folder, click on Data sources and then on the data source. On the next page click Sync now. The indexing might take a couple minutes. Wait for it to be completed.
-
Repeat step 3. Attempt to search for “Parsectix” again. You should now see some relevant content and the filenames where this content was found.